
1629 K Street NW #300
Washington, DC 20006
Google continues to be the most utilized search engine ever developed. With well over 100 TB worth of traffic from 63K queries per second amounting to 5.6 billion searches per day, Google’s position in the business of search engines is unparalleled.
Furthermore, Google’s total internet traffic volume share is over 90%.
This leaves less than 10% to Yahoo, Bing, Baidu, Yandex, and DuckDuckGo.
With authority as enormous as Google, any content that finds its way into the internet hardly stands a chance from its crawling algorithms.
Staying away from Google is almost impossible.
What happens when harmful content finds its way into the internet, if that is the case?
Can we blindfold Google from finding it? If it finds it eventually, is there anything we can do to make Google forget about it?
Remember, Google can sometimes be a Mama Coco with all its memory.
It can remember very well. It can also forget.
We would assume that you want some information off Google’s sight.
Honestly, this is possible. However, you would have some digging deep to do.
Your digging would help figure out the best approach around your problem.
We will show you how to go about taking down unfavorable content.
However, we would first understand the implications of a negative Google listing.
Table of Contents
Google does produce its content.
However, this does not count much in its share of the internet.
It has access to more than 90% of the internet.
There is “nothing” that can escape its knowledge.
With a reach like Google’s, a lot is possible.
See some below.
Google works at an enormous speed.
At that rate, it can update its bank of URLs every second.
On average, about 15% of the websites it crawls each time are entirely new to its database.
There are minimal chances of exclusion from its reach if this is the case. If it has not crawled a website, it will do so soon.
This feature of Google enables it to collect information from every possible site on the internet (except they hosted it on a local network).
If this happens, it implies that anybody anywhere can know anything about you by simply typing your name on the Google search bar.
There are chances that you may not always be at the top, but Google can always identify you.
Google’s AI puts together a series of criteria in delivering content to its users.
That means searching for “Isaac the plumber” would deliver a more direct output than “Isaac Mills.”
To make the search process more accessible, Google identifies the device from which the internet user makes the search and makes its recommendations.
Hence, it would effectively collect local data ahead of data farther away.
Read More: How To Delete Content From ScamPulse.com
That should not surprise you. Google does not interfere with the processing of information through it.
It only interferes when visitors who want certain content removed evoke its legal code. If there is no complaint, the content stays there.
Even though this code could apply to Google LLC’s other products like YouTube, it hardly holds water on the search engine.
Google just rakes up information and delivers it to those that seek it. It has little business with the content itself.
However, Google’s algorithms ensure that the terms of queries are satisfied in its deliveries.
Whenever someone publishes content on the internet, it becomes accessible to Google’s spiders.
After Google saves it in its index, it shows up on related searches – as long as it remains relevant.
Thus, the tendency of its appearance becomes subject to the presence (or absence) of other relevant content on the internet.
The search terms are the key to isolating the ranking domains.
Newer and more relevant content is an effective strategy for overcoming this limitation, as the sections below demonstrate.
Google is the most versatile online resource known to man.
It is typical of the mathematical googol from which it got its name.
Like googol, the amount of data available to Google is almost immeasurable.
It also adds more information to its gallery daily.
At its commencement in September 1997, the developers of Google (then known as PageRank) tried to define the strength of web pages by analyzing their network.
To this day, Google continues to probe this network between web pages to index them for access to visitors.
To help you understand Google’s operation system, we have tried to simplify it in the paragraphs below.
If Google has indexed sites with your name, a simple search for the name will show what it has kept in memory.
It would also crawl through more sites on the internet that bear similar content and index them.
Thus, the indexing step creates a website bank ordered in the ranks and files of information they contain.
It modifies its ranking algorithms daily. This is a significant reason why documenting this part might be difficult. However, the program shows contents in order of their relevance.
Understanding the cause of “relevance” has continued to be a subject of inquiry. Ranking, however, determines the order in which Google displays its web search results.
Google, put simply, is a search engine with its claws in over 90% of the internet.
If it has not listed anything yet, it will do so soon.
When it does, getting the information out becomes another matter altogether.
Before we decide how to go about the content on the internet, we would have to determine if it is worth going after.
The process could be overwhelming at some point.
Hence, any effort at it needs to be appropriate.
The first step to take is to ascertain the kind of content.
This will determine if one should go about removing it or not.
If this appraisal comes out negative, the content could remain.
You need not read on.
However, if the outcome is positive, something needs to be taken down.
The next step would be to decide the difficulty of taking down the content. See below.
Read More: How To Remove Content From GripeO.com
If you put up an ugly post on your Facebook wall, it would not take more than 30 seconds to take it down.
Why? It is your account.
If a friend did the posting, you might have to do minor work.
Depending on the level of friendship, you might have to wait from a couple of seconds to forever to have it removed.
How about a post on a page that does not belong to you or your friend? There are slimmer chances of control here.
This is how some sites work.
Depending on their policy or the general guidelines, you might just have your name etched on their walls “forever.”
When this is the case, Google keeps finding them.
Since Google takes information from other websites, removing the content from the original sites will stop showing up in Google search results.
This might take a while in some cases.
However, if done correctly, it would pay off.
We would analyze the content categories and determine the best course of action.
When you own the content website, you can always take down the range.
You can delete the page from your end.
When you do this, the page appears void to search histories and browsers.
You can go ahead to ask Google to remove it from its memory.
This is “de-indexing.”
Like the original action of indexing, Google will take down the URL from its cache’s servers, and it will stop showing as well.
To Remove URL’s from Google, use Google’s outdated content tool.
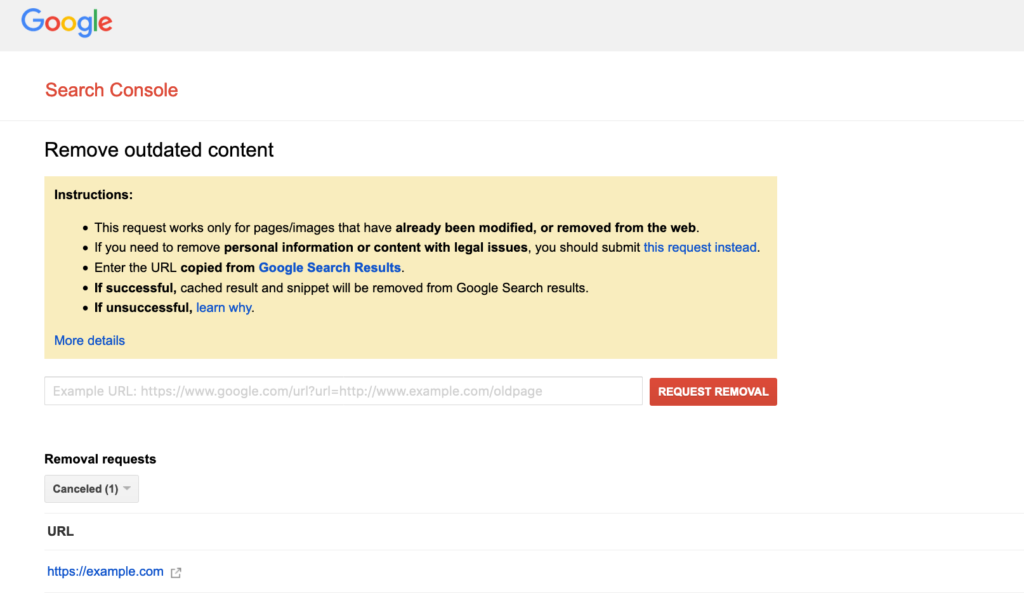
The feature will enable Google to confirm that the page link is dead.
Upon confirmation, Google will remove the link entirely from showing up in response to user queries.
You can also own content on another website (as you possess an account on Facebook).
Some sites like CheaterLand.com would allow registered users to take down content they posted.
You can just take down the content if you fall into that category.
To know if a site will allow you to take your content from their site, check their terms of service page.
This will enable you to know the best course of action.
If you can remove the content, go ahead and do so.
Sometimes, you might be the content owner but might be restricted from taking it down.
You can contact us for a comprehensive insight into the content removal process with sites like that.
See more here.
Whether you can take down content or not, Google’s spiders will always be able to find them.
There is a second category of persons. They are those with little or no control over the content.
These persons need a different approach to taking down content.
If you do not belong to the first category, you might have a chance at the second.
This category involves people that have someone else publish their content without their approval.
It also includes content that violates the rules of internet publishing.
In this case, if someone posts content that belongs to you on the internet, you can ask the site and Google to take it down.
For Google, the content will show up in search results nonetheless.
It will also feature it alongside the original material.
However, taking down such content is subject to following some laid down procedures.
There are various ways to go about it. We list them below:
Method 1:
Removing content that violates copyright laws requires a legal path.
The first method is to ask the website to take it down.
To take down content from a web page or a complete webpage, the complainant has to tender adequate information as provided in the site’s terms.
For an example of such terms, see our information on scamion.com and cheatereport.com.
When these terms are satisfied, the site can take down the content.
Upon removal, Google can also de-index the page URL.
Method 2:
Sometimes, the published content does not necessarily infringe on copyright content.
Instead, it may feature content that is inappropriate for public viewing.
In this case, you can also approach the site to take down the content.
Content that is inappropriate for public viewing include
Check here for more information on Google’s copyright policy and inappropriate content removal.
To take down such content, you would have to provide the necessary information required by law.
Upon providing the necessary information, you can approach the court to serve a DMCA take-down notice on the website.
The website admins can successfully take down the web page or the content in question if this pulls through.
Due to complexities associated with the CDA in the US and similar legislation in other countries, a total takedown of user publications is not always feasible.
However, you can be sure of relief.
Approaching Google to de-index the site is also possible. This is especially when the site cannot directly edit the post or refuses to do so (see RipOffReport.com).
Unfortunately, you may find yourself in a mix with content that you cannot either take off by yourself or ask the site to take off.
This is a real mix.
This is usually the case when someone makes a report against you for which you are guilty. It is worse when there is no trace of the publisher. Thus, you have to take extreme measures to save yourself from the implications.
Some sites like RipOffReport.com offer a corporate advocacy program that gives such persons the opportunity to apply for a paid removal.
These services could cost about $5,000 and above depending on the category for which the person subscribes.
Though ridiculous, removing the page or information would save the individual from Google’s spiders.
If this seems very difficult for you, you can contact us to do it for you with more convenience and less cost. (See what our clients say about us).
There is a need to get up and work in all categories listed above. In most cases, you would have to contact an experienced attorney.
The court processes retrieval of documents and deliveries would often cause loss of time and business opportunities.
This is why the services of an online reputation management agency like Remove Reports cannot be over-emphasized.
If it does turn out that the above methods of removal seem impossible, way too expensive, or time-consuming, you can opt for Remove Reports’ other alternatives.
Read More: How To Delete Content From ScamPulse.com
Since we now know that Google responds to the pieces in a search query, we can align with that query to outdo the previous content.
Sounds much you say.
Let us put it this way: we would provide Google with alternative search results that would weaken the position of the existing content.
If you were some sort of blogger or news agency, it would be quite an easy task to weaken the previously unfavorable content.
If you are not, there might be a problem.
This is one area Remove Reports would help save your business.
While you try to keep your business running, Remove Reports would be helping Google see other sides of you regardless of a bad review.
Though this action does not remove a negative report from Google search, it makes it possible for Google to locate the better part of you while ignoring the opposing side.
Promoting Positive Content
Besides publishing better content, sending negative content deep in the search results is a step that you need to take to stay safe.
Review sites like Dirtyscam.com and ComplaintsBoard.com are common sites for defamation.
Unfortunately, very few sites provide avenues for customers and other classes of individuals to create better information about the people they transact with.
This limitation is another opportunity that Remove Reports consider when helping its clients maintain a positive reputation on the internet.
Since Google ranks pages in order of their relevance, Remove Reports promotes relevant content at the expense of harmful content.
Thus, a search for your identity on Google with the keywords associated with the negative content would throw up the positive content. What can beat that?
Like the other strategy, this one does not delete the content. However, it is just a matter of time before it completely goes off Google’s radar.
Since most content management strategies consider the ranking characteristics of the pages, it is imperative to note them.
Generally, Google ranks pages in order of their relevance.
Relevance would mean keyword density (for some), backlinks (for others), contextualization, and many others.
These criteria account for only a fraction of what will make Google’s algorithm respond.
Thus, it is best to be up to date with Google’s analytics.
When deleting content from Google’s index is not feasible, it is best to displace them.
The action of displacing them brings one face-to-face with the realities of Google’s intelligence.
As stated earlier, this program’s flexibility and enormous versatility require one to apply an array of skills that can match Google.
Otherwise, you stand no chance of success.
The intricacies associated with this kind of program necessitate the need for thorough professionals like Remove Reports.
We do not apply amateur techniques in the business of branding and rebranding.
We also take your online portfolio very seriously.
If you can secure your content publishing on the below websites, it will outrank the negative content and put the positive content forward top the top results.
Most of the websites allow free content publishing.
Above listed sites are highly authoritative in terms of domain and page authority. It helps suppress damaging content while pushing positive content on google’s top 10 search results.
We work with 100’s authoritative websites and help suppress harmful content from Google’s first page.
Read More: Remove Content From Defaulters.com
For anyone with an identity that needs to be preserved, a positive online presence is significant.
Google will keep processing content to answer queries sent to it.
With each search, it probes the internet for anything that relates.
If you want to stay on the good pages, you should create a positive portfolio.
Such a portfolio would be challenging to beat if a damaging statement surfaces.
Google does not create content to defame anyone.
It has to collect as much as possible whenever someone serves it a query.
This is why it is essential to look out for one’s reputation on the internet – regardless of the website.
Conclusion
Remove Report is a good match for a report that surfaces on Google search.
We can effectively isolate any content you assign to us and help process its removal from Google search results.
If the circumstances do not allow us successfully remove the content altogether, we can effectively process its removal from the top.
This will ensure that it does not show in Google’s initial pages.
1629 K Street NW #300
Washington, DC 20006

123-12 Jamaica Ave, RH
New York, 11418